Building the Harness: Why Every AI-Native Org Needs a GenAI Platform Team
Every AI-native enterprise needs a GenAI Platform Team to build the harness: the engineering layer around the model that makes agents safe, observable, and economical at scale.
On this page ▾
Every company I talk to right now is “doing AI.” Engineering teams are spinning up agents, prompts, RAG pipelines (often anchored on a vector store), and eval scripts at impressive speed. The demos look great.
Then I ask one question: “Who owns the part that’s not the demo?”
The room goes quiet.
That’s the gap a GenAI Platform Team exists to close. This post is a short walk through the operating model I think every enterprise needs to adopt if it wants to be genuinely AI-native, not just AI-curious.
The problem: ten teams, ten harnesses
Without a platform team, here’s what happens. Team A builds a customer-support agent. Team B builds an incident-response agent. Team C builds a coding assistant. Each team rebuilds the same scaffolding from scratch: how the agent talks to tools, how it’s observed, how it’s evaluated, how it’s stopped from doing something stupid.
This scaffolding has a name. I call it the harness: the engineering layer around the AI model that makes it safe, observable, and useful in production. The model is the engine. The harness is the chassis, the brakes, the dashboard, the seatbelts.
The wasteful part isn’t that ten teams build ten agents. It’s that ten teams build ten harnesses. And worse: most of them are missing critical parts.
A GenAI Platform Team’s job is to build the harness once, well, so every product team in the company can compose agents on top of it.
The picture
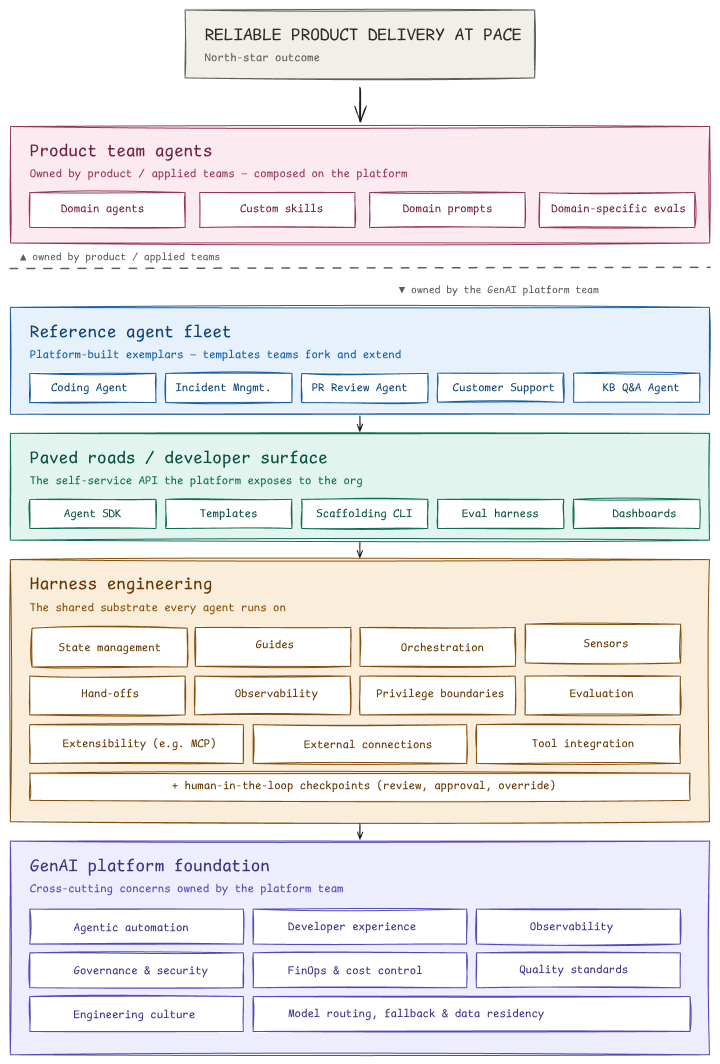 GenAI Platform Team operating model
GenAI Platform Team operating model
Read it top-down. The north star at the top (reliable product delivery at pace) is what the whole stack is justified by. Everything else exists to serve that outcome.
Top of the stack: where the value shows up
Product team agents (the pink layer) are what users actually touch. A coding agent for engineers, a support agent for the contact center, an underwriting assistant for risk analysts. These are owned by product teams, not the platform team, because product teams understand their domain better than anyone else.
This is the most important boundary in the entire diagram, marked by the dashed line: product teams own the agents; the platform team owns the substrate they run on. If you blur this line, the platform team becomes a bottleneck and product teams lose autonomy. Keep it sharp.
Middle of the stack: what the platform team builds
Three layers, all platform-owned.
Reference agent fleet (blue). The platform team builds a few exemplar agents (a coding agent, an incident management agent, a customer support agent, and so on) not because the platform owns these forever, but because building them proves the harness works and gives product teams templates to fork. Think of them as “reference implementations.”
Paved roads / developer surface (teal). This is what product teams actually touch when they build their own agents. An SDK for writing agents. Templates to start from. A CLI that scaffolds a new agent in thirty seconds. An evaluation harness that’s pre-wired. Dashboards that just work. Paved roads is a term borrowed from infrastructure engineering: the platform team paves the most-traveled paths so product teams don’t have to cut their own through the jungle.
Harness engineering (amber). This is the heart of the platform. It’s everything an agent needs to run safely and observably:
- Sensors: checks and signals that catch when an agent is going wrong (more on this below)
- Guides: context and instructions that shape agent behavior
- Orchestration: running multi-step agent workflows, with retries and fallbacks
- State management: keeping track of what an agent has done and what it knows
- Hand-offs: passing work between agents, or from agent to human
- Observability: knowing what every agent is doing, end-to-end traces
- Privilege boundaries: what an agent is allowed to do (it can suggest a database migration; it cannot run one without approval)
- Evaluation: measuring whether agents are actually doing their job well
- Extensibility: plugging in new tools, often through emerging standards like MCP (Model Context Protocol)
- External connections and tool integration: how agents reach the rest of the company’s systems
- Human-in-the-loop checkpoints: the explicit moments where a human reviews, approves, or overrides an agent
Every one of these is a hard engineering problem. Solving them once, centrally, is the entire economic case for a platform team.
The foundation: what holds it all up
GenAI platform foundation (purple) is the cross-cutting concerns: the things that touch every layer. Developer experience. Observability. Governance and security. FinOps and cost control. Model routing, fallback, and data residency. Engineering culture. Quality standards.
Two of these deserve a callout. FinOps: AI inference is expensive and the bill is unpredictable. Someone has to own spend visibility, model routing (use the cheap model when you can, the expensive one when you must), and budget alarms. That someone is the platform team. Governance: in regulated industries, which model touched which data and where the data went are first-class questions. The platform team makes the answer auditable.
The zoomed-in part: how the harness keeps agents honest
The most important detail in the diagram is the panel on the right: the sensors and steers model.
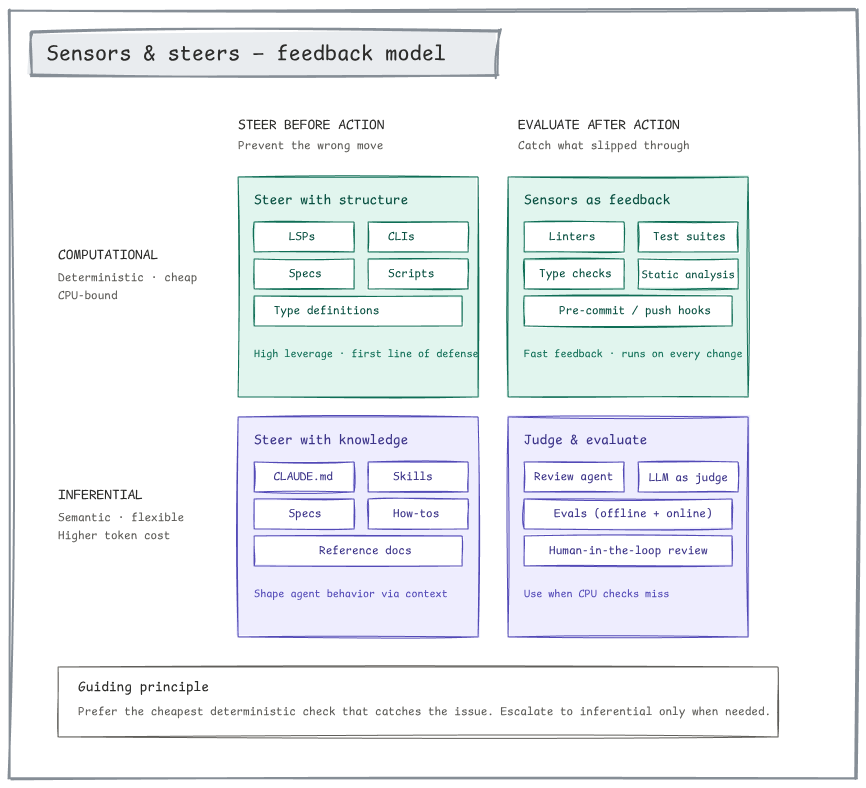 Sensors and steers 2x2: computational vs. inferential feedback, before vs. after action
Sensors and steers 2x2: computational vs. inferential feedback, before vs. after action
Agents make mistakes. The question is: how cheaply can you catch them? The framework splits feedback into a 2x2:
| Steer before action | Evaluate after action | |
|---|---|---|
| Computational (deterministic, cheap) | Types, specs, schemas, linters in your prompt scaffolding | Tests, type checkers, linters, pre-commit hooks |
| Inferential (semantic, expensive) | CLAUDE.md, skills, how-tos, reference docs | LLM-as-judge, review agent, evals, human review |
The guiding principle: prefer the cheapest deterministic check that catches the issue. Escalate to an LLM-based judgment only when a deterministic check can’t do the job.
This sounds obvious. It is not what most teams do. Most teams default to “ask another LLM to check” because it’s the most familiar tool. That’s expensive, slow, and non-deterministic. A good harness pushes work down and left on this matrix, toward cheap, deterministic, structural checks.
Why this matters for being “AI-native”
Becoming AI-native isn’t about adopting AI. Adopting AI is the easy part; anyone with a credit card can do that. Becoming AI-native is about every team being able to ship AI capabilities safely, observably, and economically, without each team becoming an AI infrastructure expert.
That only happens when there’s a paved road. And paved roads only exist when there’s a team whose job is to build them.
That team is the GenAI Platform Team. The diagram above is its scope. The harness is its product. And the outcome it’s measured on is the same outcome every engineering org cares about: reliable product delivery at pace.
If this resonates and you’re thinking about how to set up a similar team in your organization, or if you think I’ve got something wrong, I’d love to hear about it. The shape of these teams is still being figured out, and the field benefits when more people share notes.